Research
Unified Hybrid Image Model
The basic element of the project's novelty is the unified hybrid image model (UHIM), which consists of the following complementary components.
First UHIM Component
A unified set of photometric image features that are estimated using machine vision algorithms. Most features are invariants for common image transformations (file format change, tonal correction, quantization, sharpening, scaling, etc.). Compared to analogues, the use of such features makes it possible to efficiently search for transformed images and adequately distinguish them from similar images. Author's technology. Such features are indispensable when there are no objects in the image that can be identified using computational intelligence algorithms.
Second UHIM Component
A unified set of image features that are estimated using the CNNs. On the basis of these features, according to the author's technique, an object-oriented description of the image is compiled. Which is very effective for searching in the presence of standard objects in the image. The list of found objects can be added to the metadata for quick search by words. Third UHIM Component
In the future, it is planned to add into the model a new technology for local feature (LF) detecting and storing. Which additionally classifies and filters LFs before storing.
Compared to analogues, this approach will leave only the required minimum of significant LFs and provide real-time search. Such LFs are needed to detect objects of a unique shape, objects / images that are inserted in other images. Which is relevant, for example, to search images under copyright protection program.
Outcomes
Compared to analogs, the components of the model complement each other to efficiently search for images in various conditions of use, taking into account the context, transformations, the presence of similar images and Big Date problems.
Technology
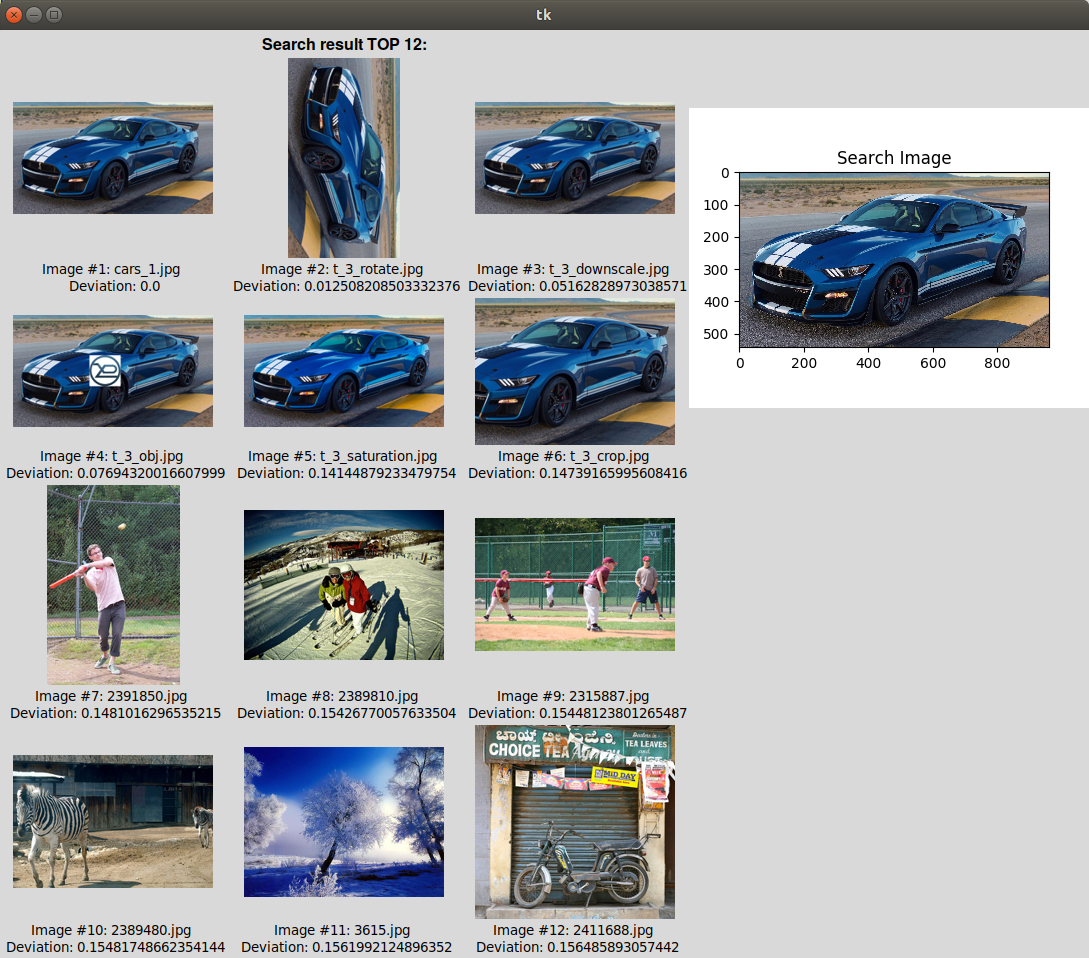
For quick search, the image features are estimated once when image placed in the storage. Image features are stored as a relatively small FLT. The search is performed on the basis of comparison and estimation of the similarity measure of the FLTs; because the FLTs are relatively small, the search is very fast. The search result is presented as a list of images from the storage, sorted in descending order by the measure of similarity with the searched image.
To implement this technology, innovative FLT model is proposed. On the basis of this FLT model, in the future, a model of a search hypercube will be built for effective search in Big Date conditions.
Outcomes
Using the proposed models and technology allows work effectively with any image storages (lake, warehouse, photobank, archive, etc.). Since the data in the image storage and its structure do not change. A small warehouse is created for each image storage, where image accounts are stored, including image FLTs and links.
Search based on the proposed model and technology assumes that instead of images, we will operate (compare, transmit over the network, etc.) with FLTs and image links. The size of which is several orders of magnitude smaller than the size of the images. In such a situation, it’s possible to significantly reduce the hardware requirements for servers and network equipment by providing real-time search. Even for Big Data.